Throughput of 1 sample per clock
Parameterized bit widths and fixed-point option.
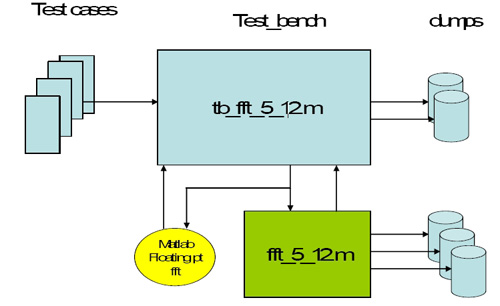
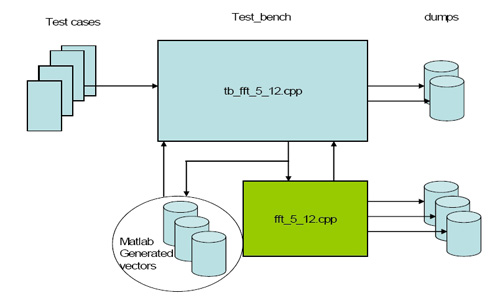
Test bench with fixed-point Matlab and optional C++ models
Available in ASIC and FPGA technologies
Minimal gate count implementation
Supports flushing and re-starting of the FFT operation instantly
Configurable bit width based on SQNR requirement for random inputs or for a specific stimuli pattern.
Customization for OFDM applications |